¿Cómo adivinar el futuro en machine learning? - Segunda parte

Como comentamos en la primera parte, los modelos de forecasting pueden ser aplicados a multitud de escenarios distintos, por ejemplo, para predecir el tiempo meteorológico o para predecir el stock de productos en una tienda. Para este caso práctico, vamos a intentar predecir la cantidad de bicicletas que se alquilan en un servicio de alquiler de bicicletas en Washington DC (USA), utilizando un modelo basado en Prophet.
Para poder desarrollar este ejemplo se ha suministrado un dataset ya procesado (weather_day.csv) y un script en python para poder ejecutar y modificar el código a gusto del usuario (prophet_qindel.py).
Descripción del dataset
El dataset con el que se va a trabajar en este caso práctico tiene un total de 731 filas y 16 columnas y se encuentra ya procesado para una mayor comodidad.
Las filas indican las series temporales con las que se va a trabajar, es decir, una fila contiene la información relativa a un día en concreto, desde el 01/01/2011 hasta el 31/12/2012. Por su parte, las columnas contienen la información diaria que se va a poder utilizar (Fig. 6).
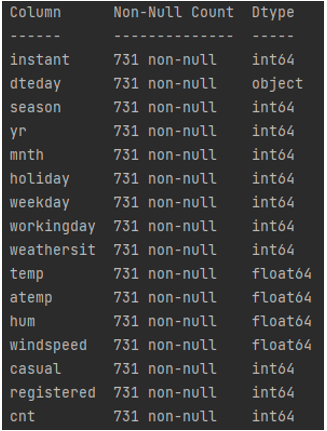
El usuario tiene total libertad para explorar el contenido de estas columnas y/o sacar gráficos para comprobar las distribuciones de las mismas. Para este ejemplo práctico vamos solamente a trabajar con:
- Dteday: indica la fecha en formato YYYY-MM-DD.
- Temp: indica la temperatura ya normalizada.
- Weathersit: indica el tiempo meteorológico. Su valor es un entero que oscila entre 1 (buen tiempo) y 4 (mal tiempo).
- Cnt: indica el número de alquileres. Es la variable que queremos predecir.
Predicción sin regresores externos
En una primera aproximación vamos a intentar predecir el número de alquileres las últimas dos semanas de diciembre (del 17-12-2012 al 31-12-2012), utilizando solamente un modelo basado en el número de alquileres previos.
Antes de comenzar, vamos a realizar una gráfica para conocer la distribución de estos alquileres a lo largo del tiempo (Fig. 7).
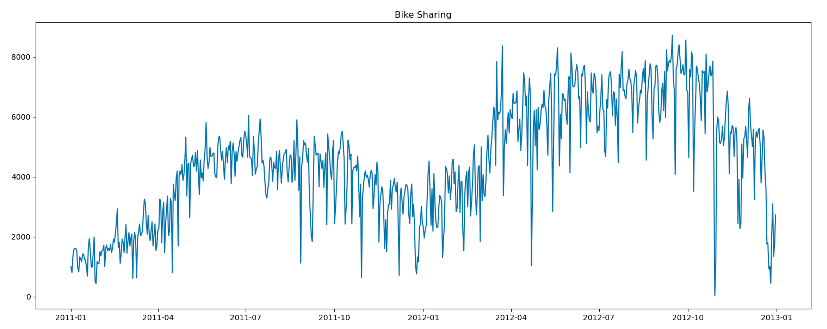
Como se puede comprobar en la gráfica, la distribución de los datos está bastante bien comportada a lo largo del tiempo. Se puede comprobar a ojo, que en los meses a priori, más calurosos (primavera y verano), el uso de las bicicletas aumenta con respecto al resto de meses del año. Además, cada año que pasa parece que la tendencia del uso de este servicio va en aumento.
Para poder usar Prophet, antes debemos procesar mínimamente nuestro dataset. Primero, es recomendable realizar un resample de los datos en caso de que no tengan la periodicidad deseada (en este caso días). Posteriormente, se deben filtrar las columnas que se van a utilizar en el modelo. Como esta primera predicción va sin regresores externos, solamente hay que quedarse con las fecha (dteday) y con la variable a predecir (cnt). Estas variables se deben renombrar a ‘ds’ e ‘y’, respectivamente, ya que son los nombres que utiliza Prophet por defecto. Por último, separamos el dataframe en dos, uno lo vamos a utilizar para entrenar el modelo (con fecha hasta el 16-12-2012) y el otro lo vamos a usar para comparar los resultados de la predicción (con fecha a partir del 17-12-2012) (Fig. 8).
Una vez el dataframe está procesado, ya se puede crear un modelo Prophet y entrenarlo sobre estos datos. Cuando el entrenamiento finalice, se podrán realizar predicciones indicando, en este caso, el número de días en el futuro que se quieren predecir. Prophet parte de la última fecha suministrada en los datos de entrenamiento (en este caso a partir del 16-12-2012).
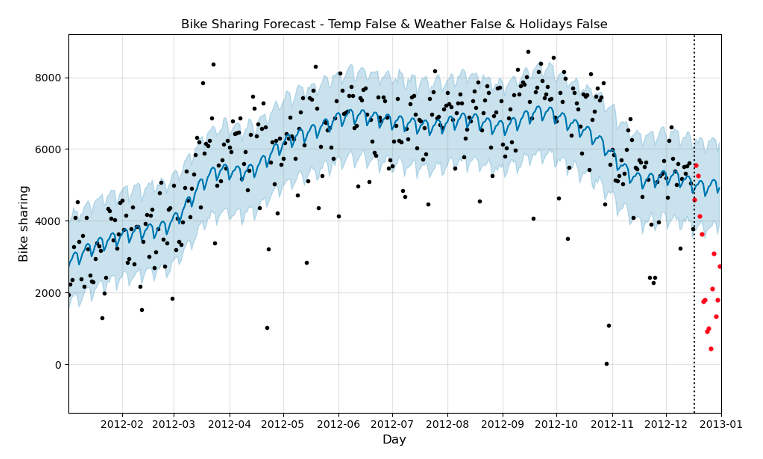
Una vez se tienen las predicciones, se pueden comparar contra los valores reales (Fig. 9).
También es posible mostrar la descomposición de los distintos componentes que forman nuestra serie temporal (Fig. 10).
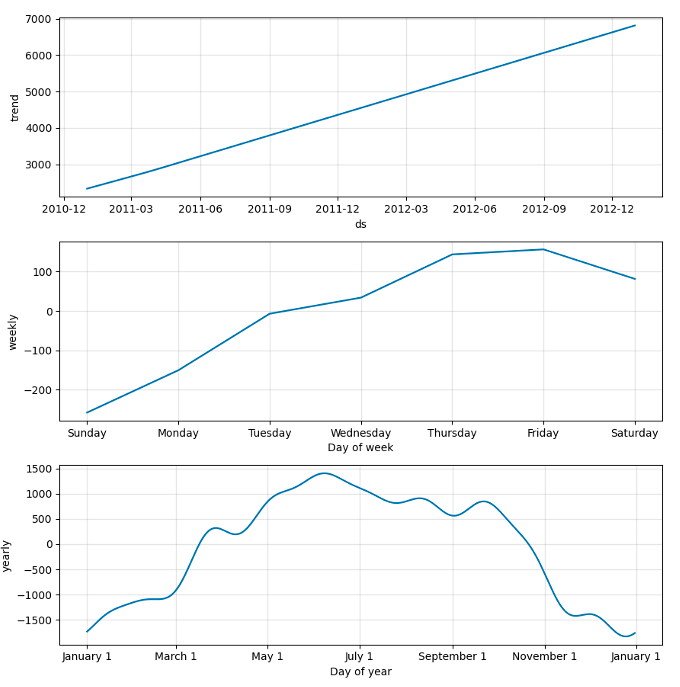
Cómo se puede apreciar en la Fig. 9, el modelo de Prophet no es capaz de capturar gran parte de los puntos, sobre todo los que contienen valores más extremos. Por ejemplo, no es capaz de detectar la bajada de casos que se produjo a finales de 2012.
Respecto a la Fig. 10, se puede observar como la tendencia de los datos es ascendente, incrementándose mensualmente. Aparentemente el uso de las bicicletas es mayor a medida que avanza la semana, llegando a su pico máximo los viernes. También, como habíamos comentado en la Fig. 7, los meses con mayor uso de este servicio ocurren en primavera y verano.
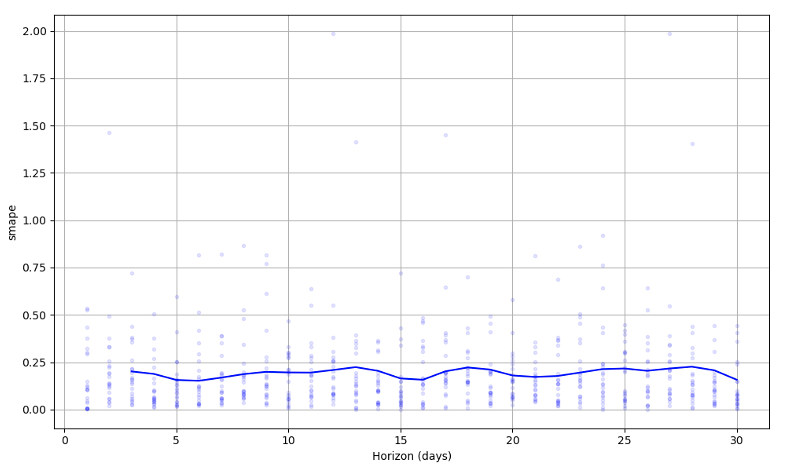
Por último, para comprobar con una métrica numérica cómo de bien o de mal se comporta este modelo, se puede realizar cross-validation sobre los datos, ya que Prophet incorpora métodos para realizar esta tarea de una manera sencilla. Para este ejemplo, se ha propuesto un horizonte de 30 días y se ha utilizado una métrica de SMAPE (Fig. 11).
Predicción añadiendo la temperatura
Para intentar mejorar las predicciones realizadas en el caso anterior, vamos a introducir los datos de temperatura como una variable exógena en el modelo de Prophet. Antes de comenzar, vamos a comprobar si la temperatura puede estar correlacionada de alguna manera con la variable que queremos predecir (Fig. 12).
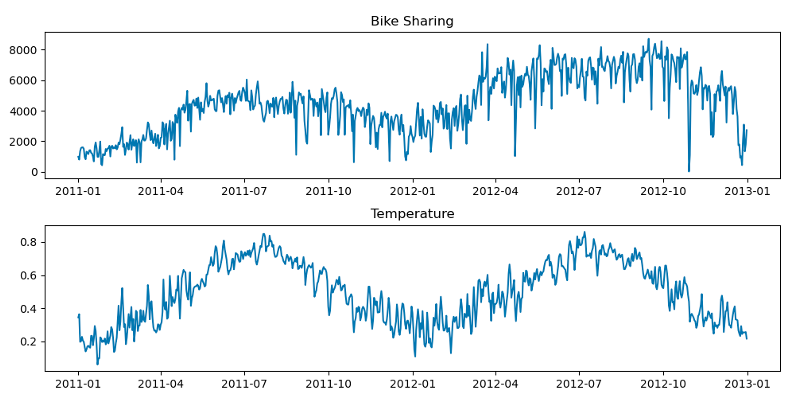
Como se puede comprobar en la gráfica, estas dos variables parecen tener algún tipo de relación en la época de primavera y verano, ya que ambas tienen picos en estos meses. Esto puede indicar que, la gente tiende a usar más el servicio de alquiler de bicicletas cuando hace una buena temperatura.
Para poder utilizar esta nueva variable, el proceso que se va a llevar a cabo va a ser prácticamente el mismo que el comentado anteriormente, con la salvedad de que hay que añadir la columna ‘temp’ al dataframe y hay que indicar a Prophet que la añada como un regresor antes de realizar el entrenamiento (método add_regressor()).
Es importante tener en cuenta que, cuando se vaya a hacer la predicción de los nuevos datos, éstos datos han de tener siempre un valor de temperatura. Para este ejemplo práctico vamos a utilizar la temperatura que tenemos en el dataframe que separamos para predecir, pero en un entorno real habría que tener una estimación para la temperatura, por ejemplo.
Una vez realizamos las predicciones, volvemos a generar la gráfica comparativa contra los valores reales y la descomposición de los componentes de la serie temporal (Fig. 13 y Fig. 14).
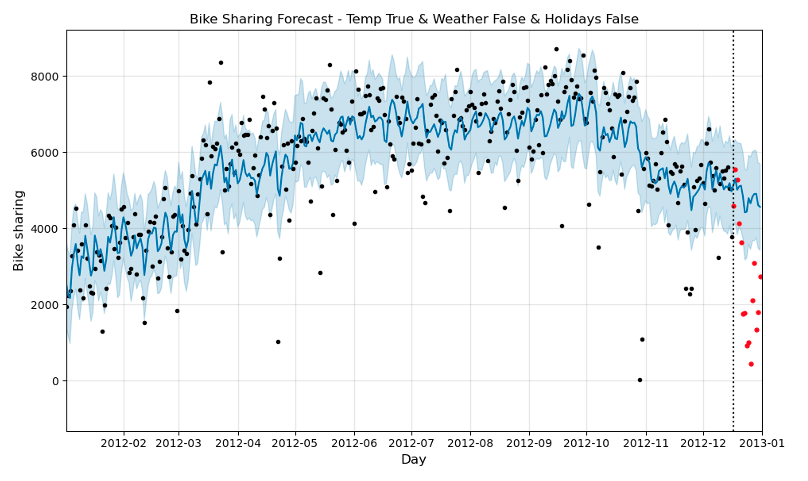
Viendo la Fig. 13, se puede comprobar como las predicciones realizadas por Prophet están mejor ajustadas a los puntos y no son tan “planas”. Esto indica que, como habíamos supuesto inicialmente, la temperatura es una variable que ayuda al modelo a realizar mejores predicciones.
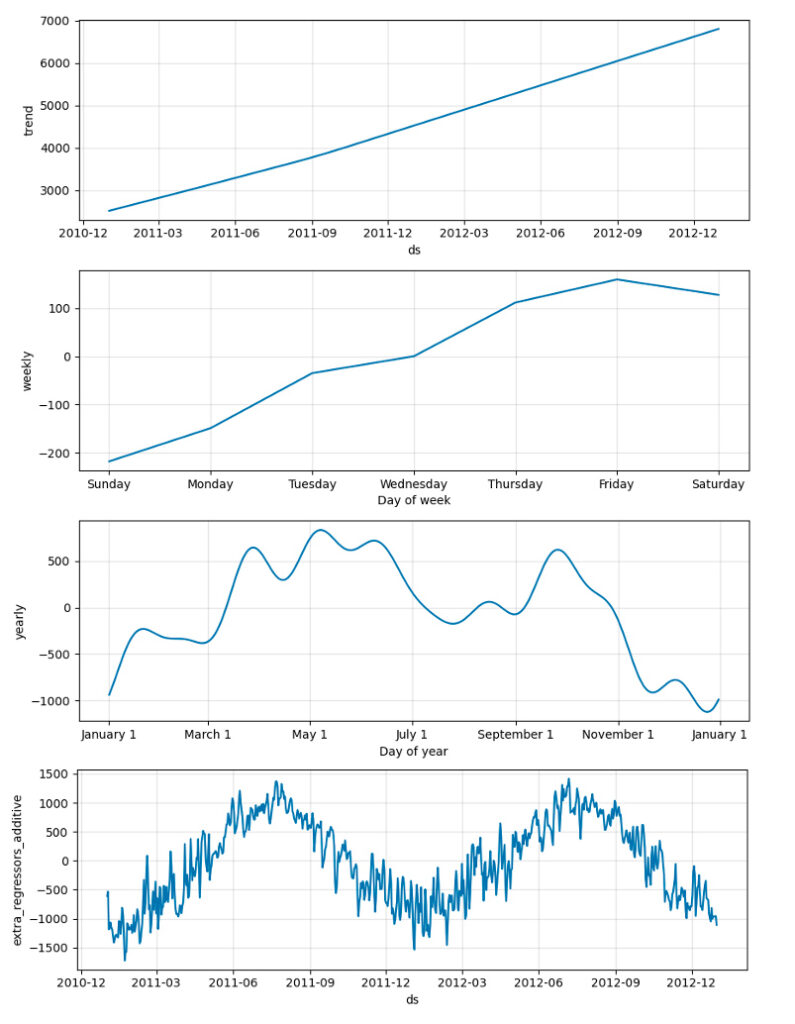
Respecto a la Fig. 14, podemos ver que ha aparecido una nueva gráfica que indica el comportamiento de la variable exógena (temperatura) a lo largo del tiempo, del mismo modo que ocurre en la Fig. 12.
Predicción añadiendo la temperatura, el tiempo y las vacaciones
En este último caso, vamos a introducir, además de la temperatura, la variable de tiempo meteorológico y los días de vacaciones en USA. Es razonable pensar, que los días con buen tiempo (sin lluvia o nieve) la cantidad de gente que utilice el servicio de bicicletas sea mayor. De un modo similar, una hipótesis válida podría ser que en días de vacaciones se utilice menos el servicio, ya que la gente no tiene que acudir a sus puestos de trabajo y no es tan necesario el uso de este tipo de transportes.
El proceso para incluir la variable de tiempo meteorológico es exactamente igual que en el caso anterior, mientras que para las vacaciones hay que usar el método add_country_holidays() de Prophet antes de entrenar el modelo.
Una vez realizamos las predicciones, volvemos a generar la gráfica comparativa contra los valores reales y la descomposición de los componentes de la serie temporal (Fig. 15 y Fig. 16).
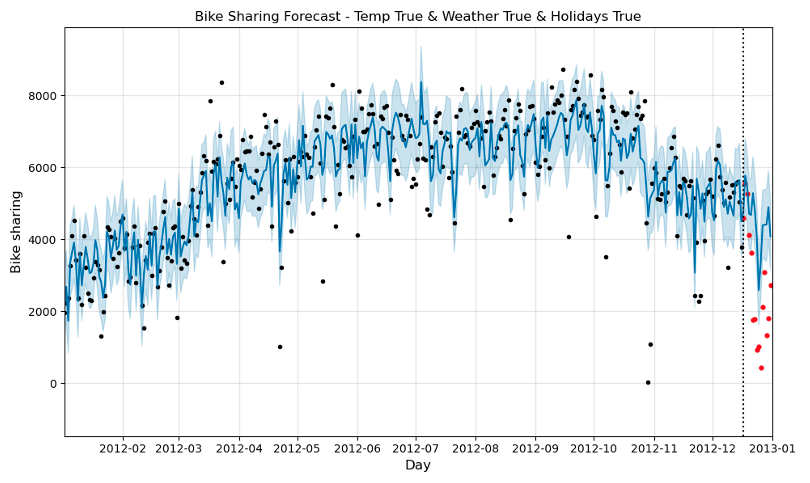
Viendo la Fig. 15, podemos ver que con la inclusión de la nueva variable exógena y de los días de vacaciones, las predicciones se ajustan todavía más a los datos reales. Se puede comprobar cómo el modelo es capaz de capturar mejor los días que hay bajadas importantes en el uso del servicio (ej. a finales de diciembre cuando hay vacaciones).
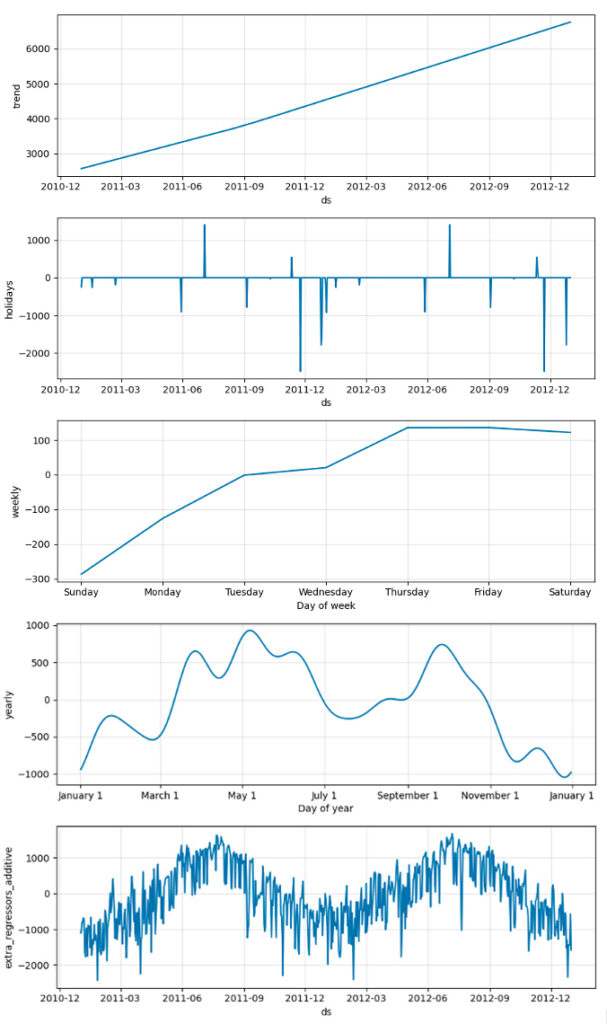
En la Fig. 16, se puede ver como ha aparecido una nueva gráfica que indica el impacto de los días de vacaciones en el país. Además, vemos que la gráfica relativa a los regresores externos ha cambiado, esto es porque se ha agregado la serie de temperaturas a la de tiempo meteorológico.
En resumen
En este ejemplo práctico se ha visto el potencial de Prophet para poder realizar predicciones a futuro sobre un caso de uso real. Se han probado distintas combinaciones de variables para comprobar las diferencias entre unas y otras y poder conocer el impacto que tienen dentro del modelo. En la Tabla 1 se muestran los distintos resultados obtenidos para cada una de estas estrategias.
Tabla 1. Resultados de las ejecuciones de Prophet.
| Temperatura | Tiempo meteo. | Vacaciones | RMSE | SMAPE (%) |
| No | No | No | 1328.81 | 19.28 |
| Si | No | No | 1271.11 | 18.41 |
| Si | Si | Si | 1128.06 | 16.34 |
Como se puede comprobar en la tabla y como ya se había comentado anteriormente, la estrategia que combina las variables exógenas de la temperatura y el tiempo meteorológico, así como los días de vacaciones en USA, permiten a Prophet realizar predicciones más exactas y precisas. A nivel de RMSE se consigue mejorar el error unas 200 unidades con respecto al caso base, mientras que el SMAPE mejora en torno a un 3%.
Contacta con nuestro equipo de soluciones machine learning para poder predecir los procesos de tu empresa.
16/03/22 Forecast, machine learning, Prophet


