La importancia de contar con un buen equipo de arquitectura rendimiento. Nuestro caso.
Uno de los puntos críticos de una empresa TIC es el correcto funcionamiento de sus sistemas. En el panorama actual, entendemos “correcto funcionamiento” no sólo al conjunto de requisitos funcionales, sino también a todos los requisitos no funcionales intrínsecos al mismo.
Dentro de estos requisitos no funcionales, la disponibilidad y la velocidad son quizás los más demandados por nuestros clientes. Para ello, el equipo de arquitectura rendimiento se encarga de garantizar dichas cualidades. Dentro de las buzzwords del mundillo, destacamos principalmente en APM y SRE.
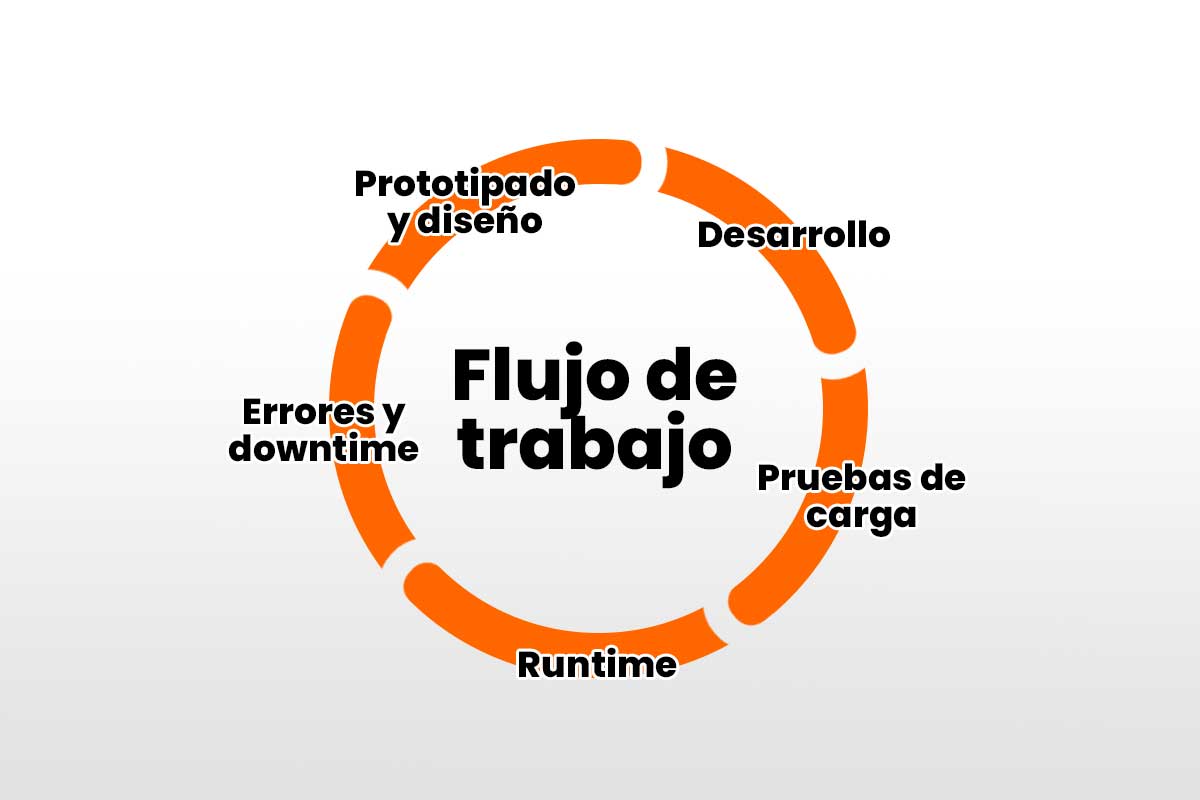
Para garantizar el rendimiento de un aplicativo, es preciso poner el foco durante todo el ciclo de vida del mismo.
Prototipado y diseño
Nuestros ingenieros de solución son los encargados de extraer los requisitos para los aplicativos de nuestros clientes.
Los clientes confían en nosotros para que nos preocupemos de aquellos aspectos que un perfil centrado en el negocio no necesita controlar, como por ejemplo de la seguridad, del rendimiento y de la escalabilidad. Es decir, creen en la profesionalidad y experiencia de Qindel a la hora de tomar la mejor decisión.
Para garantizar estos requisitos no funcionales, hacemos que sean explícitos durante el ciclo de vida y realizamos un shift left para poder tenerlos siempre en cuenta. Durante esta fase se plantea una arquitectura (Microservicios, eventual, CQRS), qué sistemas de almacenamiento se van a emplear (SQL, noSql, S3, Kafka, Pulsar, cachés), y en qué proveedores a desplegar Openshift, AWS, Azure…
Desarrollo
Durante el desarrollo, el equipo de Arquitectura rendimiento se encarga de solventar dudas, propone algoritmos eficientes y revisa con los equipos los posibles cuellos de botella. Entre las tecnologías que el equipo suele emplear, quizás java y spring son las más destacadas.
Para realizar esta labor, empleamos una gran variedad de herramientas, como por ejemplo jprofiler, jifa, visualvm o wireshark.
Gracias a esto podemos identificar una gran cantidad de problemas:
- Consultas lentas a base de datos que han de ser revisadas con un Explain Plan.
- Identificar problemas de rendimiento n+1.
- Detectar problemas de rendimiento en el garbage collector como OOMKills, Memory churn, etc.
- Problemas de deadlocks o de usos indebidos de los distritos threadpools.
El poder trabajar en estos puntos durante el desarrollo permite reducir la cantidad de problemas en un futuro. Esto a su vez minimiza el coste y facilita el correcto desarrollo. En el mundo IT, el poder detectar un error lo más temprano posible implica un ahorro importante.
Además, se recomienda el uso de patrones de resiliencia en los distintos puntos de las aplicaciones. Circuit breakers, retries, backpressure o feature toggles son los que ponemos más en práctica.
Pruebas de carga
Durante el desarrollo, una feature no se marca como resuelta si ésta no ha pasado sus pruebas de rendimiento apropiadas. En ellas estresamos la plataforma y el caso de uso, pudiendo comprobar que los tiempos y cargas definidas son alcanzables. Para ello hacemos uso de tecnologías como Jmeter o K6 donde modelamos los flujos de los usuarios y validamos que la solución cumple la especificación
Runtime
Mientras la aplicación se encuentra funcionando, es preciso contar con la mayor cantidad de información posible de esta. Una arquitectura basada en servicios ha de contar con un buen sistema de monitorización. Es por eso que nuestro equipo dispone de una gran cantidad de información a su alcance a través de grafana.
Mediante el uso de Métricas, Trazas y Logs, el equipo puede identificar qué servicios se ven afectados en rendimiento, pudiendo detectar problemas cuando los distintos SLOs dejan de cumplirse y detectando la causa raíz del problema.
Además, el disponer de esta información permite modelar mejores casos de uso en las aplicaciones, lo que a su vez permite mejorar todavía más los casos de las pruebas de rendimiento y retroalimenta el sistema.
Con el objetivo de que el equipo sea escalable y detecte dichos errores de forma rápida y efectiva, utilizamos sistemas de alertado y notificación de alertas para así detectar problemas en el rendimiento de forma casi inmediata. Incluso se habilita en multiples ocasiones el uso de monitorización sintética para poder observar distintos comportamientos en producción.
Errores y downtime
Pese a todo lo anterior, los errores acaban sucediendo. Sin embargo está en manos de un buen equipo minimizar el downtime que un servicio puede afrontar, en medida de lo posible. Para ello, la única forma para llevarlo a cabo es experimentar estos problemas mediante simulacros con el fin de emular situaciones de downtime como, por ejemplo, reinicios de máquinas, latencias en red, computo o similares durante sesiones de chaos testing. De tal forma que un equipo se familiarice con las distintas herramientas y pueda afrontar un problema en producción cuando este se produzca.
Conclusiones
Los miembros de los equipos de arquitectura rendimiento son profesionales con mucha experiencia, capaces de trabajar en los distintos niveles y capas de complejidad del software y que entienden la importancia de minimizar los errores. Son personas que acaban convirtiéndose en referentes dentro de los equipos de desarrollo debido al valor y tranquilidad que generan. Sin embargo, esta sensación es muy posible que no permee en las capas altas de la organización.
Debido a su propia naturaleza, un equipo de rendimiento que hace su trabajo de forma correcta puede pasar desapercibido puesto que "todo va bien". Con el objetivo de evitar esta casuística, disponer de informes de mejoras, problemas detectados con anterioridad, disminución del número de incidencias o mejoras en los tiempos de resolución de las mismas, son claves para justificar el valor que aporta. Además estas medidas objetivas ayudan al propio equipo a mejorar día a día y a mantener una actitud de mejora continua.
23/02/22 arquitectura rendimiento, metodología de trabajo, TIC


