¿Cómo buscamos imágenes parecidas usando redes neuronales?

La búsqueda de imágenes similares es una tarea común que podemos encontrar en gran variedad de aplicaciones. En la mayoría de los casos la entrada es una imagen y la salida debe ser una o más imágenes similares. En la imagen 1 podemos ver algunos ejemplos para diferentes significados de la palabra “similar”.
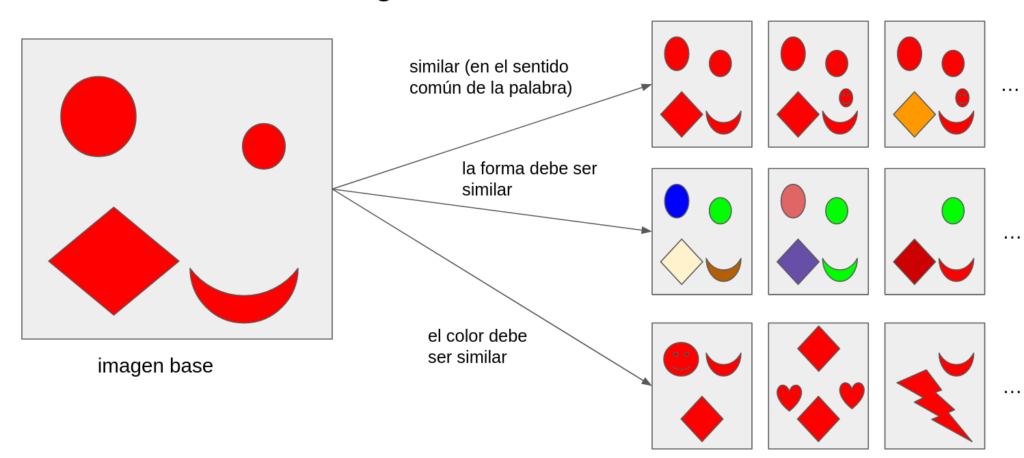
Para diseñar un sistema suficientemente flexible decidimos basarnos en los modelos de redes neuronales profundas (si la tarea fuese encontrar imágenes idénticas o relativamente poco diferentes de una imagen base se podrían usar otros métodos como la función hash perceptual). En el resto de este texto explicaremos cómo se puede construir un modelo de redes neuronales capaz de buscar imágenes similares.
¿Cómo construimos un modelo usando redes neuronales?
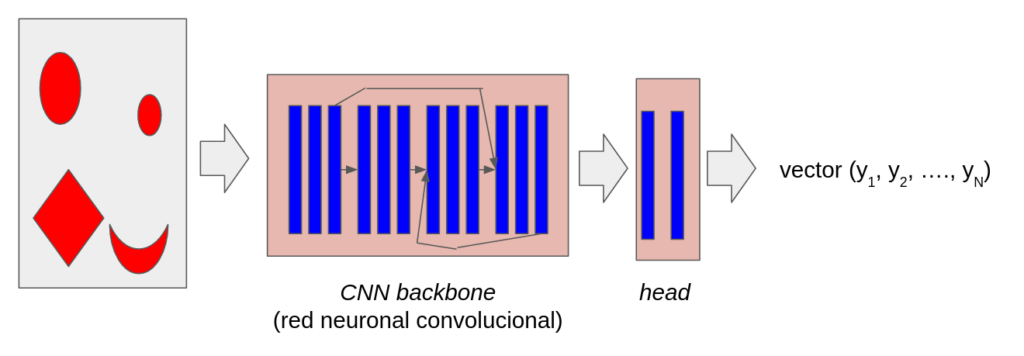
En la imagen 2 podemos ver la idea básica: queremos tener un codificador capaz de convertir una imagen arbitraria en un vector de N componentes (embedding). La idea es que el vector resultante represente coordenadas en un espacio de N dimensiones. Los puntos relacionados con dos imágenes similares deben estar cerca en ese espacio de N dimensiones, mientras que dos imágenes diferentes estarán colocadas lejos.
¿Cómo entrenamos una red para que discrimine imágenes?
El procedimiento de entrenamiento que usamos se basa en la idea de triplet loss[2]. La clave consiste en la selección de tripletes de imágenes:
- Una imagen base (anchor)
- Un ejemplo similar (imagen positiva)
- Un ejemplo diferente (imagen negativa)
El triplet loss es una función que mide la separación entre la base y los ejemplos positivos y negativos:
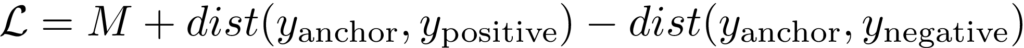
En la ecuación, dist es la distancia (p.ej. Euclidiana) entre los vectores que representan las imágenes. Cuánto más cerca está el ejemplo positivo a la imagen base y/o cuanto más lejos está el ejemplo negativo, más bajo será el valor de la función. La constante M representa el margen del triplet loss (la distancia mínima que debe separar los ejemplos positivos y negativos).
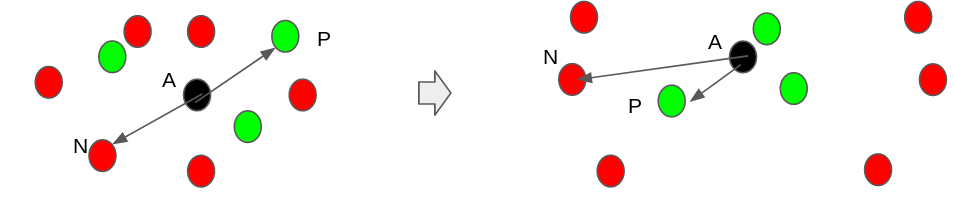
El algoritmo de entrenamiento modificará los pesos de la red neuronal para que el valor de la función objetivo siempre vaya bajando. En la imagen 3 podemos ver una ilustración del entrenamiento.

Para acelerar el proceso de entrenamiento se puede usar una versión especial de la función objetivo llamada batch hard loss[3]. En la imagen 4 podemos ver una ilustración.
El entrenamiento se acaba cuando el valor de la función objetivo deja de bajar. En este momento se guardan los pesos de la red y pueden ser usados en el futuro para convertir cualquier imágen en su representación numérica apta para ser comparada con representaciones numéricas de otras imágenes con el objetivo de determinar si son parecidas o no.
¿Cómo definimos imágenes positivas y negativas?
Esta es la parte más importante del entrenamiento. El criterio con el que seleccionamos imágenes positivas y negativas determinará el comportamiento del modelo. En la imagen 5 vemos un ejemplo que usamos para entrenar una red capaz de encontrar imágenes idénticas (o muy parecidas). Los positivos son una variación muy pequeña de la imagen base. De esta manera la red es capaz de encontrar versiones de la misma imagen (recortes, resoluciones diferentes, cambios de color).
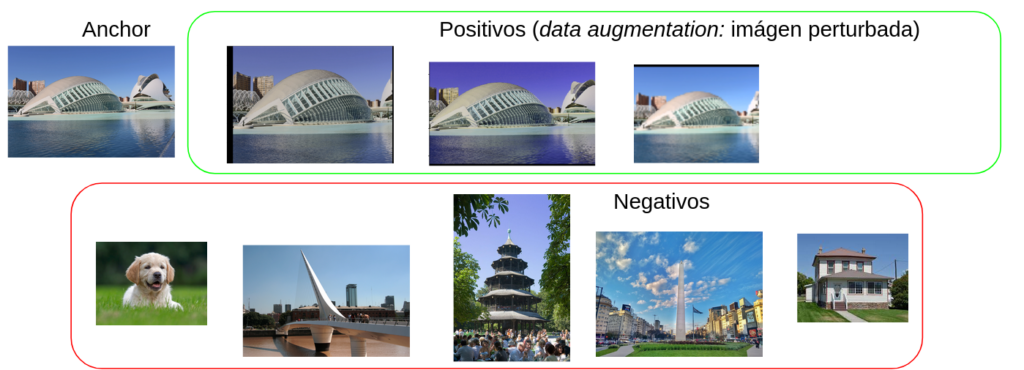
Por otro lado, también podemos entrenar una red capaz de encontrar imágenes con la misma categoría de objetos, aunque no sean versiones de la misma imagen. En la imagen 6 podemos ver un ejemplo.

La selección correcta de imágenes positivas y negativas es crucial para obtener el resultado deseado.
Ejemplos
Entrenamos una red para que busque imágenes parecidas. En la imagen 7 mostramos algunos ejemplos.

Como podemos ver, la red es capaz de encontrar imágenes parecidas razonablemente bien. Sin embargo, vemos que las distancias en la primera fila son mucho más pequeñas que en los otros dos ejemplos. Eso se debe al hecho que hay mucha menos variedad en hojas[4]. En el caso de los edificios hay más variedad y por eso las distancias son mayores. Sin embargo, podemos ver que, en el caso de la torre Eiffel, en la imagen más parecida el edificio está posicionado en el mismo lugar en la imagen (a la derecha del centro), mientras que las siguientes imágenes muestran cada vez más diferencias con respecto a la imagen base. En la última fila la imagen base es la segunda imagen más parecida a la torre Eiffel. En este caso vemos que el orden de las imágenes parecidas cambia, pero que los resultados siguen siendo consistentes con los vistos en la segunda fila.
Conclusiones
En este artículo mostramos cómo se puede entrenar una red neuronal que calcula un vector (embedding) asociado a una imagen, con el objetivo de usar ese vector para calcular distancias con otras imágenes. Las principales ventajas de este método son:
- Los modelos son fáciles de construir y usar empleando librerías comunes (p.ej. Keras)
- El método es adaptable a diferentes clases de problemas cambiando la definición de imágenes positivas y negativas.
- El método permite entrenamiento iterativo (los modelos van mejorando con el tiempo y el entrenamiento se puede parar en cualquier momento para validar el modelo).
Las principales desventajas son:
- Si la definición de los ejemplos positivos/negativos es equivocada, el modelo resultante dará resultados indeseados.
- El entrenamiento es un proceso de muestreo aleatorio del conjunto de imágenes. El modelo resultante puede ser más o menos universal dependiendo de las propiedades del conjunto de entrenamiento. Cuánto más universal el conjunto, más general será el área de aplicabilidad del modelo.
Una de las implementaciones del modelo usando triplet loss se puede encontrar en nuestra página de GitHub: https://github.com/qindel-ml/siamese-nn/blob/master/train_triplet_loss.py
[1] La red neuronal convolucional puede ser una de las conocidas y bien estudiadas redes disponibles en p.ej. Keras (https://keras.io/api/applications/#available-models).
[2] Para la definición formal y más información puede consultar la página en Wikipedia: https://en.wikipedia.org/wiki/Triplet_loss
[3] Para más información puede leer el artículo “In Defense of the Triplet Loss for Person Re-Identification” de Hermans A., Beyer L. y Leibe B. (2017, https://arxiv.org/abs/1703.07737).
[4] Las imágenes de hojas son parte del conjunto plant_leaves de TensorFlow (https://www.tensorflow.org/datasets/catalog/plant_leaves).
Autores: P. Mimica y S. Gutiérrez
20/12/21 imágenes, redes neuronales


